Build a Time-Series ARIMA Model for Stock Market Forecast in Python
4 minutes
July 1, 2022
In this article, ARIMA algorithm will be introduced and we will talk about how to build a time-series ARIMA model in Python to make real-time forecast for stock market.
Here is the content in this article:
Content:
- What is ARIMA?
- Stock Market Forecast Codes in Python
What is ARIMA?
ARIMA stands for “Autoregressive Integrated Moving Average” and it is an algorithm for forecasting time-series data, such as predicting stock market price, or forecasting daily temperature.
ARIMA is composed of three parts:
I. AR (Autoregression):
- It is a linear combination of lagged dependent variables i.e., observations
- Parameter Notation: “p”, the number of lag orders
- Formula:
II. MA (Moving Average):
- It is a linear combination of lagged error terms between actual and forecast values
- Parameter Notation: “q”, the number of lagged forecast errors
- Formula:
III. I (Integrated):
- The differences between original observations and lagged ones to make the time series data stationary.
- Parameter Notation: “d”, the number of difference levels
- Formula (take the 1st difference level as an example, i.e., d = 1):
Stock Market Forecast Codes in Python:
In this session, we take Facebook/Meta data via yfinace API to build an ARIMA model to forecast the next minute stock price.
The datetime library will let us obtain the duration of time from retrieving data to forecast the next minute stock price.
The time_series module contains the functions we need for making the prediction on stock market price.
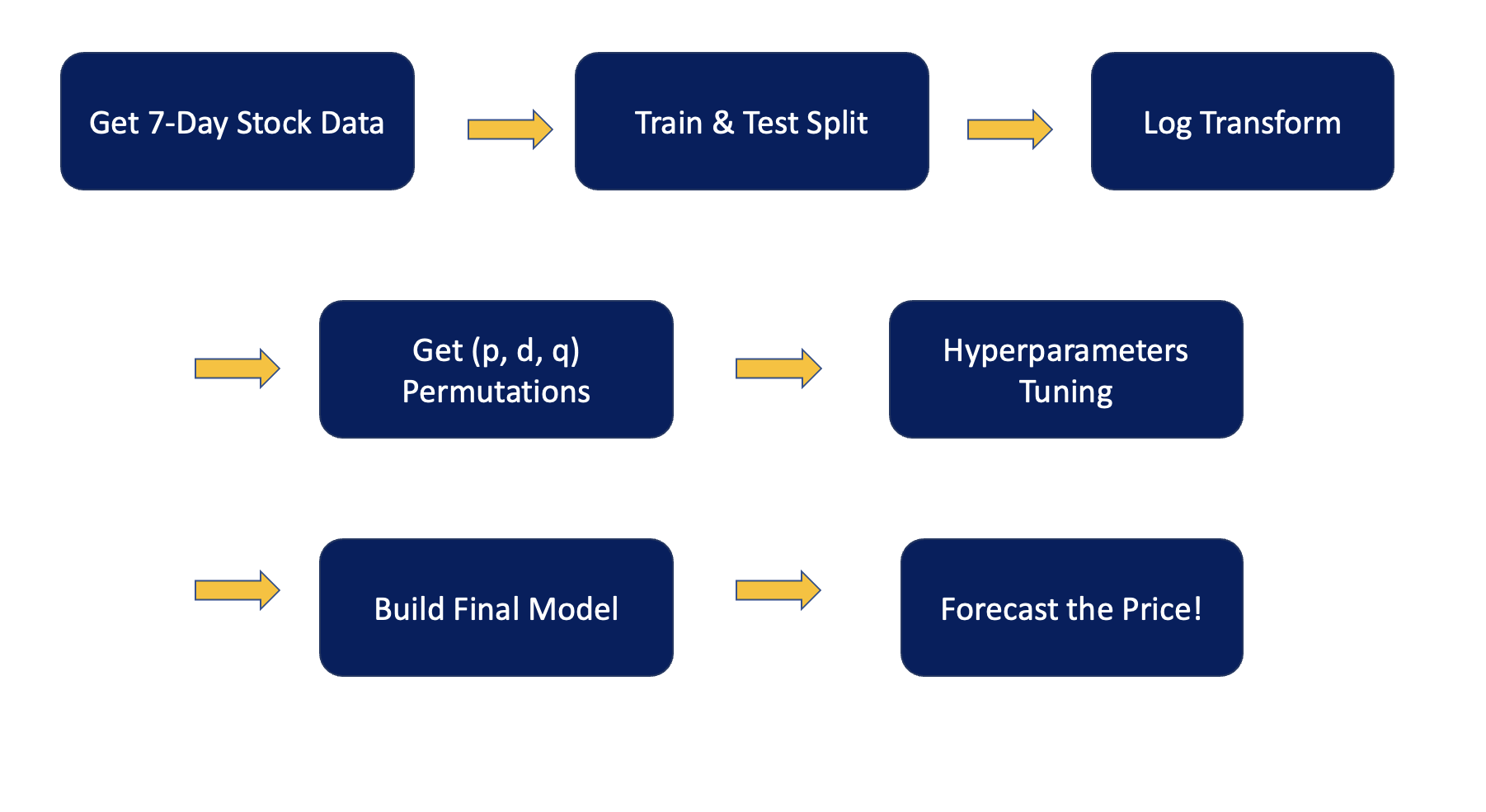
II. Instantiate the class and get 7-day stock price:
ts=Time_Series()stock=ts.get_data('meta')
By using yfinance API, we can obtain 7-day of stock data by minute.
III. Train & Test Split:
train,test=ts.split()
In a time-series problem, the data are in sequence, which means we will not split the data into train and test randomly, so here we take the last 50 observations as our test data due to computer power constraint.
IV. Log transform:
train_1,test_1=ts.make_log()
We take natural logarithm (log(1+x)) to flatten the fluctuation.
V. Get (p, d, q) permutation:
params=ts.generate_params()
We generate different combinations of (p, d, q) for hyperparameters tuning to find out the smallest RMSE (Root Mean Square Errors).
VI. Hyperparameters Tuning:
rmse_box,best_pdq=ts.rmse_calculation()
How to train a time-series model?
When building a time-series model, we get a forecast for the next timestamp based on the data from the previous timestamps which means, your train data size will gradually increase for each iterations (see the detail codes in the GitHub link below) cause we want to forecast the "next timestamp."
For example, your last timestamp of train data is “2022-06-27 15:56:00”, and you build a model from the train data, so you get a forecast for “2022-06-27 15:57:00.” What if we want to see the forecast of “2022-06-27 15:58:00”?
Then, you will add the actual observation of “2022-06-27 15:57:00” to train data, and this timestamp will be your last observation in the train data. You’ll build a model from this “new” train data, and get a forecast for the next minute which is “2022-06-27 15:58:00."
Here we use the “forecast()” function from ARIMA to get “out-of-sample” forecast.
Thus, the code above performs hyperparameters tunings to iterate different permutations of (p, d, q) and to see which permutation yields the smallest RMSE.
VII. Build final model:
ts.final_training()
We train the whole 7-day data with the best (p, d, q) permutation we obtain from hyperparameters tuning job to get a forecast for the next minute (refer to the picture below)!
Below are the full codes:
defexecute():"""This function is to execute all the functions to get
the next minute open price.
Returns
-------
str
a message to show the next minute open price & the total
processing time
"""try:# create the beginning timestamp for calculating # the runtimet1=dt.datetime.now()# instantiate the classts=Time_Series()# get the 7-day of stock data by minutestock=ts.get_data('meta')# train and test splittrain,test=ts.split()# take log on both of train & test data to flatten #the fluctuationtrain_1,test_1=ts.make_log()# generate the p, d, q permutationparams=ts.generate_params()# hyperparameters tuning to get the smallest RMSE # with corresponding p, d, qrmse_box,best_pdq=ts.rmse_calculation()# train the whole data with the best p, d, q obtained # from hyperparameters tuning and show the next minute # forecastprint(ts.final_training())# get the timestamp to obtain the timedelta of runtimet2=dt.datetime.now()# get the runtimereturnf"total processing time: {(t2-t1).seconds} seconds"exceptExceptionaserr:print(err)# execute the functionexecute()